
Oversight Models for AI Security: Human in the Loop vs. Human on the Loop
- J. Nacol and AI Assisted Research
- Apr 26
- 5 min read
As agentic AI integrates into enterprise systems, selecting the appropriate oversight model is a fundamental security and compliance requirement. The architecture of human control is now as critical as technical safeguards like encryption or access management.
1. Defining the Oversight Models
Enterprises often use these terms interchangeably, but they represent distinct operational and security strategies.
Human-in-the-Loop (HITL): Humans are embedded within the decision pipeline. The AI cannot complete actions without explicit human validation at checkpoints. Humans act as active participants who provide real time approvals.
Human-on-the-Loop (HOTL): The AI executes decisions independently, often at machine speed. Humans monitor outputs, audit behavior, and intervene only when anomalies are flagged or thresholds breached. Control is supervisory and reactive, not transactional.
AI-in-the-Loop (AI²L): This is a distinct third model, not a variant of HITL. In AI²L, the human is fully in control, with the AI serving as an assistant that synthesizes information, surfaces options, and presents consequences.
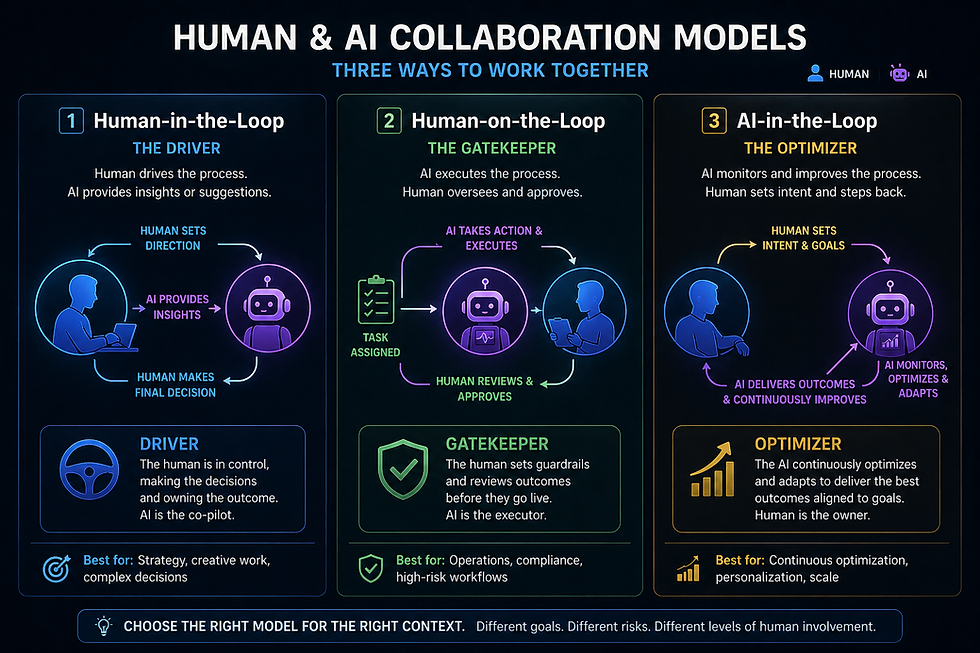
Here's a side-by-side comparison of all three models:
Feature | Human-in-the-Loop (HITL) | Human-on-the-Loop (HOTL) | AI-in-the-Loop (AI²L) |
|---|---|---|---|
Who drives? | AI drives; human gates | AI executes; human monitors | Human drives; AI assists |
Control | Human validates at checkpoints | AI autonomous; human intervenes on exception | Human decides; AI synthesizes options |
Latency | Minutes to hours | Minimal | Varies by human pace |
Throughput | Limited by human capacity | High, scalable | Moderate |
Bias Sources | Historical data, model construction | Historical data + automation bias in human review¹ | Human judgment + AI synthesis bias |
Intervention | Proactive, integral | Reactive, supervisory | Continuous human direction |
¹ Automation bias in supervisory roles is well-documented in human-factors research (Parasuraman & Manzey, 2010).
3. The Security Implications of Each Model
What Each Model Gets Right and Where Each One Breaks Down
HITL Security Strengths: HITL provides stronger safeguards for auditability and regulatory compliance. By requiring human validation, organizations reduce the risk of unchecked autonomous errors in high-stakes, irreversible decisions. This is non-negotiable in contexts where liability, ethics, or patient safety are on the line.
HITL Security Weaknesses: Attackers can exploit HITL's inherent latency to delay fraud detection, buying time to exfiltrate data before approval workflows complete. At scale, human cognitive fatigue causes "rubber-stamping," where humans approve AI recommendations without genuine scrutiny, undermining the very control HITL was designed to provide.
HOTL Security Strengths: HOTL enables faster operational tempos and the ability to monitor vast datasets at machine speed. Real-time anomaly detection can identify deviations far faster than human review of every action, making it essential for high-volume environments like SOC operations.
HOTL Security Risks: Without robust monitoring or fail-safes such as circuit breakers, unchecked AI actions in HOTL can compound errors rapidly, causing cascading failures before human intervention occurs. Accountability gaps emerge when audit trails are incomplete. Explainability tools are not optional in HOTL; they are the mechanism by which humans can audit AI decisions by highlighting which input features drove a given output.
Adversarial Exploitation of Oversight Models
Neither model is immune to deliberate attack and security teams must design for exploitation, not just operational failure:
HITL exploitation: Attackers can social-engineer the humans embedded in the approval workflow. A well-crafted phishing campaign targeting a financial analyst who approves AI-flagged transactions could authorize fraudulent transfers that the AI correctly held for review. The human becomes the vulnerability.
HOTL exploitation: Adversaries can poison training data to shift anomaly detection thresholds, causing the monitoring system to treat malicious behavior as normal. By gradually moving the baseline, attackers evade the supervisory layer entirely—and no human review is triggered.
4. Industry Use Cases: Matching the Model to the Mission
High-stakes, low-volume decisions → HITL: Medical diagnosis support, legal document review in high-impact cases, financial fraud adjudication, and critical infrastructure configuration changes all demand human judgment, ethical reasoning, and clear accountability.
High-volume, lower-stakes operations → HOTL: A SOC team managing 10,000 daily alerts cannot run HITL on each one. HOTL with defined escalation thresholds allows the AI to handle routine alerts and surface only the most critical (such as those which may initiate a network block or disable a group of accounts) for human review.
The regulated industry calculus: In healthcare, finance, and critical infrastructure, the "choice" is often constrained by regulation. HIPAA, the EU's DORA, and the EU AI Act increasingly mandate minimum oversight levels for high-risk AI systems, effectively requiring HITL for certain processes regardless of efficiency considerations.
5. The Governance Gap — Why Model Choice Alone Isn't Enough
Picking a Model Is Step One. Governing It Is the Hard Part.
The most common enterprise failure point isn't the model selected—it's the governance gap that follows, often stemming from insufficient governance practices.
For HITL Governance:
Define specific checkpoints: Use concrete thresholds (e.g., "All transactions above $1,000 require human approval before execution").
Provide actionable decision support: Present humans with synthesized risk signals, not raw data.
Monitor and cap cognitive load: Set and enforce limits (e.g., no more than 50 approval decisions per hour per reviewer).
Audit the auditors: Track approval rates and time-per-decision.
For HOTL Governance:
Document escalation criteria explicitly: Every HOTL deployment needs clear thresholds specifying when the system escalates and to whom.
Treat logging as the security layer: Comprehensive, immutable audit logs are the primary accountability mechanism when AI operates autonomously.
Deploy explainability tooling: SHAP, LIME, or counterfactual explanation tools must be integrated before deployment, not added retroactively.
Test anomaly detection adversarially: Regularly probe whether your monitoring thresholds can be gradually shifted by data drift or deliberate poisoning.
6. The Practical Path Forward To Designing a Hybrid Model
Most Enterprises Need Both Models Running in Parallel
For most enterprise environments, the binary framing of HITL or HOTL is a false choice. A tiered, adaptive oversight strategy where the risk profile is matched to each decision is the practical path forward.
Tier 1 (HITL): Irreversible, high-impact, or legally sensitive actions. The agent must obtain explicit human approval before execution. Examples: high-value loan approvals, medical treatment recommendations, core infrastructure changes.
Tier 2 (HOTL): Reversible, moderate-risk actions. The agent executes autonomously, with rigorous logging and exception-based human review. Examples: fraud alert triage, moderate-risk security remediation, customer service responses.
Tier 3 (Full Automation): Low-risk, high-volume, fully auditable actions where errors are minimal and easily corrected. No human review unless anomaly thresholds are breached. Examples: transaction categorization, log aggregation, routine data processing.
Cultural enabler: Beyond technology, a hybrid model demands shared vocabulary and shared accountability between AI development and security teams. Governance breaks down when architectural decisions are made in isolation from risk management.
7. The Decision You Can't Afford to Defer
The distinction between Human-in-the-Loop and Human-on-the-Loop is foundational to your enterprise's security posture. HITL embeds humans directly into the execution pipeline, demanding explicit validation. HOTL positions humans as supervisors of autonomous execution, intervening on exception. AI²L is a third model—distinct from both—where the human leads and the AI assists. None is universally correct. Your choice must be deliberate, context-aware, and rigorously governed.
Start by auditing your current AI deployments: map each automated decision to a risk tier, document escalation rules, and pressure-test override paths. If you can't answer "Who owns the override?" for a high-risk AI deployment, you've found your first governance gap. Fix that before your next agentic AI goes into production.


Comments